必须得让AI明白,有些不该碰的东西别碰(doge)
AdaTooler-V团队 投稿
量子位 | 公众号 QbitAI
近期,以DeepEyes、Thymes为代表的类o3模型通过调用视觉工具,突破了传统纯文本CoT的限制,在视觉推理任务中取得了优异表现。
然而,一个问题逐渐显现:视觉工具用得越多,模型真的更聪明吗?
大量实验发现,许多模型正在陷入“盲目用工具”的状态——即便任务并不需要,也会条件反射式地调用裁剪、抽帧、区域放大等工具。
结果却是:推理路径更长了,算力消耗更高了,准确率却没有同步提升,甚至在部分任务中出现下降。
这并不是工具不够强,而是模型从来没有学会一件事:什么时候真的值得用工具。
来自港中文MMLab等的研究团队,针对这一核心问题提出了AdaTooler-V——一个具备自适应工具使用能力的多模态推理模型,让模型学会判断“该不该用工具”,而不只是“怎么用工具”。

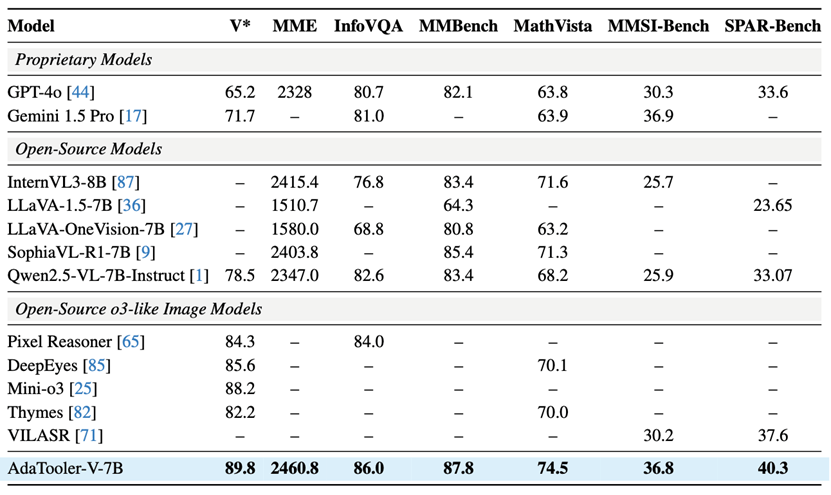
在12个主流图像和视频推理基准上,AdaTooler-V展现出了显著优势。例如,在高分辨率视觉推理任务V上,AdaTooler-V-7B的准确率达到*89.8%
工具使用的有效性探究
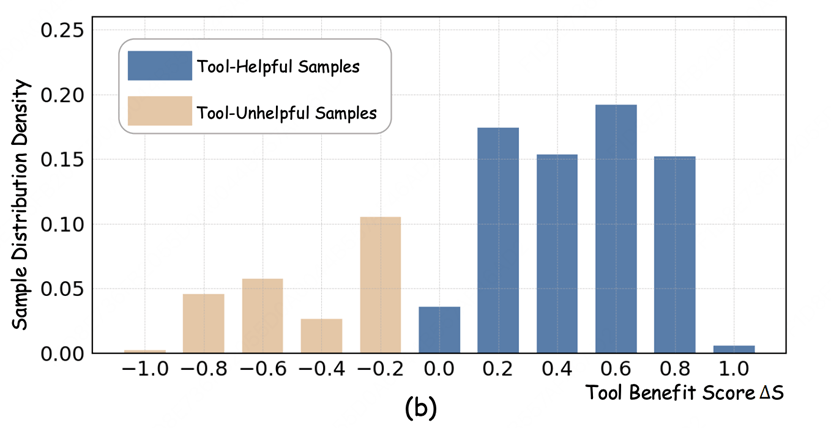
研究团队引入了一个关键指标——Tool Benefit Score(工具有益分数),用于量化视觉工具调用在所带来的真实性能增益。
具体而言,该指标通过比较同一问题在“使用工具”和“未使用工具”两种条件下的表现差异,判断工具调用是否产生了实质性的正向贡献。
如图所示,在相当一部分样本中,工具的引入不仅未能提升模型性能,反而导致结果出现明显下降。
AT-GRPO:让模型学会判断“该不该用工具”
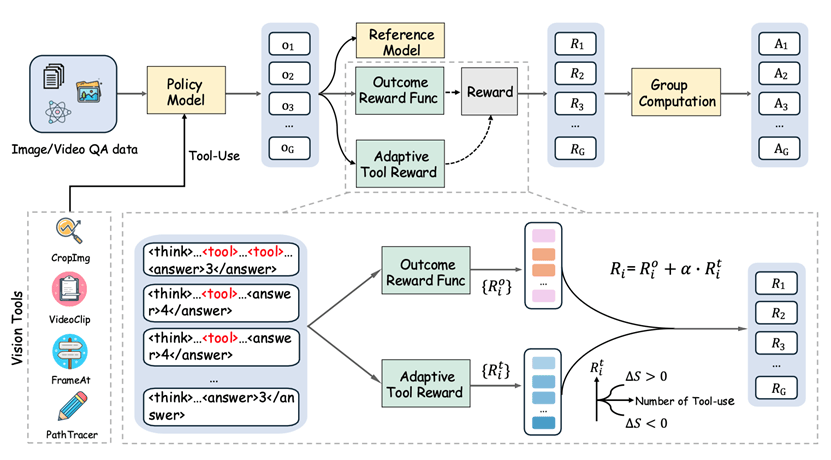
为此,团队提出了全新的强化学习算法AT-GRPO算法用于训练模型的自适应视觉工具调用能力。
思路很简单:只有当工具确实带来性能提升时,模型才会因为工具使用获得正向奖励;当工具无效甚至有害时,工具调用本身会被惩罚。
实验结果表明,AT-GRPO使模型能够自主学习一种既有利又具备良好泛化能力的推理策略,在优化模型性能的同时有效降低推理成本。
多模态工具调用数据构建
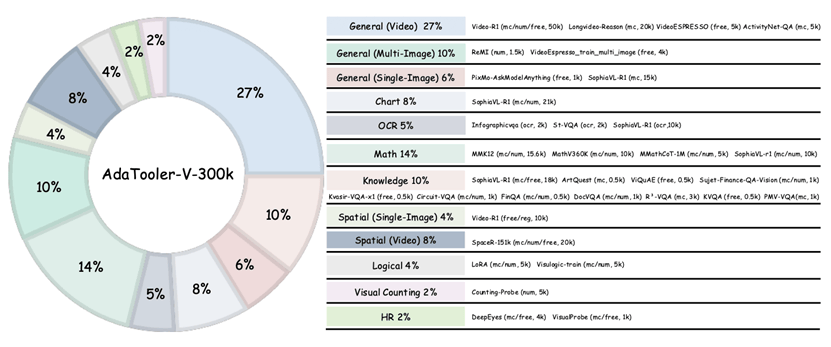
为了支撑训练,研究团队构建了两套大规模数据集:
AdaTooler-V-300k:用于强化学习阶段,覆盖单图、多图与视频三种模态,涵盖数学、计数、空间理解、逻辑推理等多类任务。
AdaTooler-V-CoT-100k:用于SFT冷启动,包含大量多轮工具交互的高质量推理轨迹。
在两阶段训练框架下,模型先通过SFT建立基本的多模态工具推理能力,再通过AT-GRPO学会自适应工具使用。
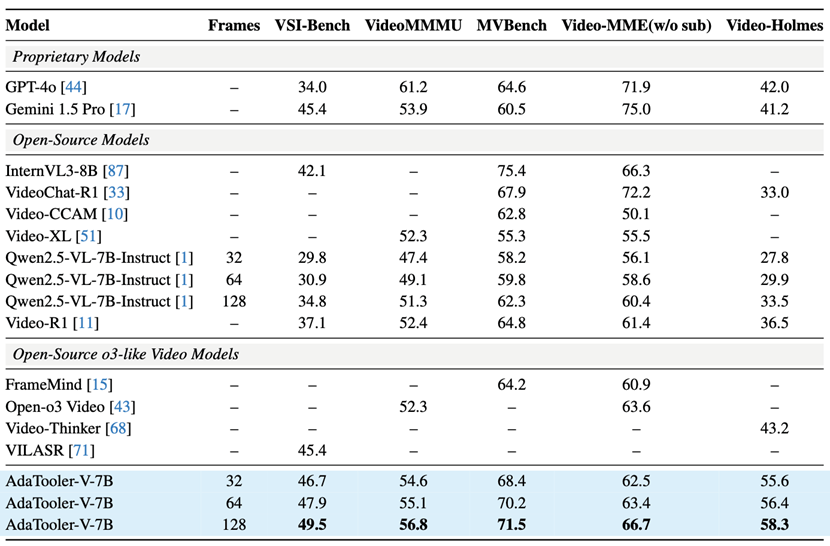
基准评测
研究团队在12个主流的图片和视频基准上进行测评。
从下表可以看出,AdaTooler-V在图像问答任务中表现出色,在MMBench上取得87.8%的准确率,在MathVista上达到74.5%。
在视频理解任务中,AdaTooler-V同样展现出显著优势,例如在VSI-Bench和VideoHolmes上分别取得49.5%和58.3%的性能表现,明显领先于其他方法。
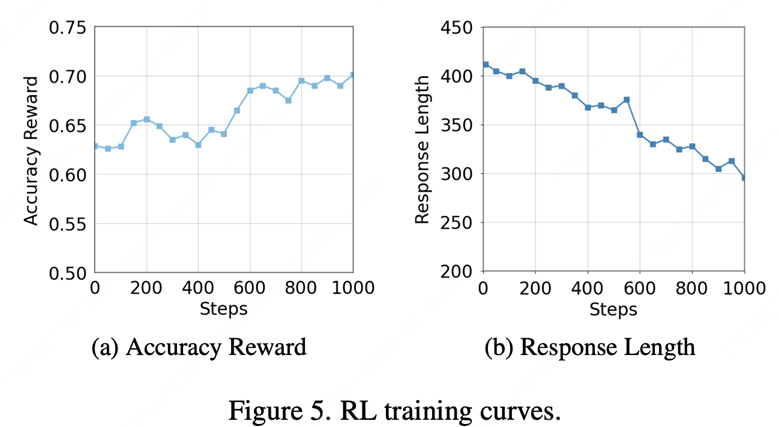
同时,从训练曲线可以观察到,随着模型准确率的持续提升,其平均推理长度逐渐下降,这表明模型正在学会在推理过程中合理选择是否进行工具调用,而非盲目地频繁使用工具。
一些AdaTooler-V的推理例子如下所示:

