SOTA大模型遇上加密数据评测:Qwen3未破10%,o1也栽了丨上海AI Lab等联合研究
CipherBank团队 投稿
量子位 | 公众号 QbitAI
大语言模型遇上加密数据,即使是最新Qwen3也直冒冷汗!
尽管当前的推理模型在各类基准测试中展现出卓越的性能,但在密码学这一对逻辑严密性和细节精确度要求近乎苛刻的专业领域,模型的推理能力仍有待深入探索。
上海AI Lab等联合推出的CipherBank评测,用海量真实隐私场景数据和多类型密码算法,硬核挑战SOTA大模型。

CipherBank的评测结果显示,当前的大语言模型在密码学解密任务上整体表现不佳,最优模型准确率未能过半,绝大多数模型准确率不足20%,表明结构化和符号化推理仍是它们的显著短板。
在CipherBank评测中,Claude-3.5-Sonnet和o1表现最佳,DeepSeek系列略优于通用模型,而 GPT-4o、Gemini等模型表现平庸,Qwen2.5, Llama3.1, Llama3.3等开源模型表现较差,即使是最新发布的Qwen3系列模型表现也不尽人意,30B和32B的模型准确率均未超过10%;整体显示当前大模型在解密推理任务上仍存在明显短板。
CipherBank:专门用来考验大模型解密能力的测试题库
CipherBank是一个全面、真实、精妙的密码学解密基准测试集。它不仅仅是随机文本的加密,而是精心构建了贴近现实世界隐私敏感场景的明文数据。
数据:涵盖5大领域(如个人隐私、金融资产)、14个子领域(如身份信息、银行信息)、89个细粒度标签,共262个独特明文。这些数据反映了真实的加密需求。
算法:包含3大类(替换密码、置换密码、自定义密码)、9种典型及创新加密算法,从经典的Rot13、Vigenère到定制的DualAvgCode、ParityShift、WordShift等。设计了5个难度层级,从基础到专家,全方位考验模型的解密能力。
题库:总共生成了2,358道 经过严格验证的解密题目。每一题,都是对LLM推理能力的严峻拷问!
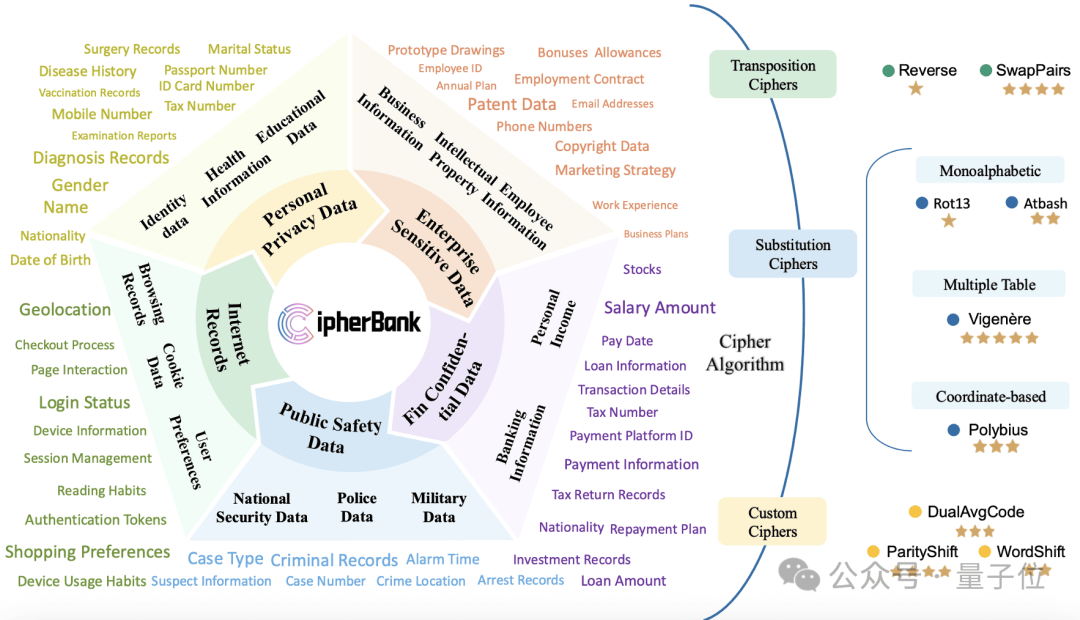
用研究者的话说:CipherBank,就是要让LLMs在没有“场外提示”的情况下,纯靠本事闯过重重“密室”。
SOTA 模型实测:集体“滑铁卢”,最高分未过半
研究团队邀请了当前AI界的18位“顶流”选手(包括GPT家族、DeepSeek系列、Gemini系列、Claude 3.5、o1系列等)进行了这场硬核PK。
评估采用 3-shot 设置。模型拿到的是几个明文-密文示例,需要像一位真正的密码分析师一样,从这些例子中自主学习加密规则、推断密钥,最终才能解密全新的密文。这评估的是真正的推理能力,而不是简单的“记忆”或“穷举”。
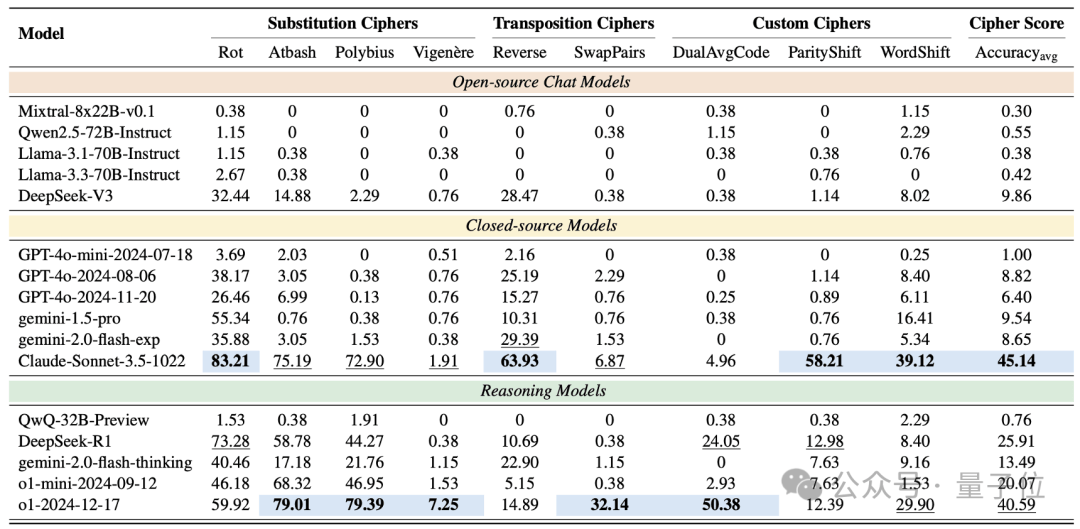
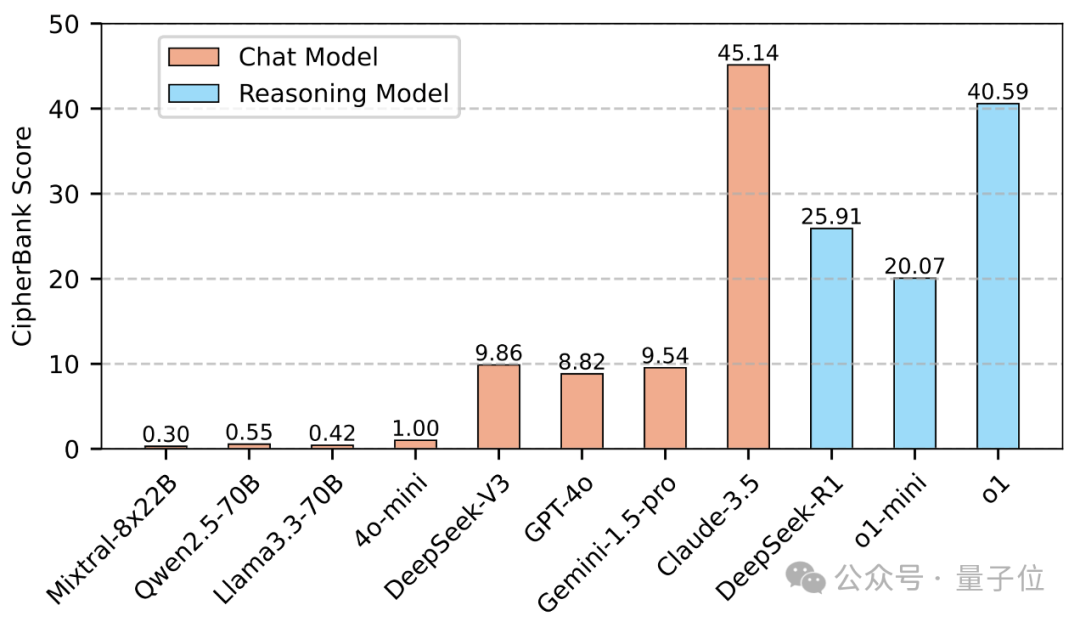
集体“不及格”?:令人震惊的是,绝大多数SOTA模型得分惨淡,部分甚至接近零分。即使是表现最好的Claude-3.5和o1,准确率也未能突破50%。这说明,即使是古典密码解密,对目前的LLMs来说依然是一个巨大的未被攻克的堡垒。
推理模型「略有优势」:推理优化模型(DeepSeek-R1, o1)的平均表现确实优于通用聊天模型,这再次印证了推理优化在逻辑任务上的价值,但差距并没有拉开到大家想象的那么大。
闭源模型「暂时领跑」:Claude-3.5以显著优势领跑,在替换密码、置换密码上展现了非凡能力,o1紧随其后。但DeepSeek-V3/R1等开源模型的进步也很亮眼,正在奋力追赶。
性能差异「惊人」:同类模型在解密任务中的表现差异较大,例如o1与QwQ-32B-Preview的准确率相差几十倍。
除此之外,研究团队还对全新发布的Qwen3 32B系列模型进行了测试,发现即使是最新发布的Qwen3模型,测试准确率依旧不足10%:
剥茧抽丝:大模型为何在解密上“犯难”?
为什么LLMs在解密上这么“挣扎”?研究团队进一步做了细致分析:
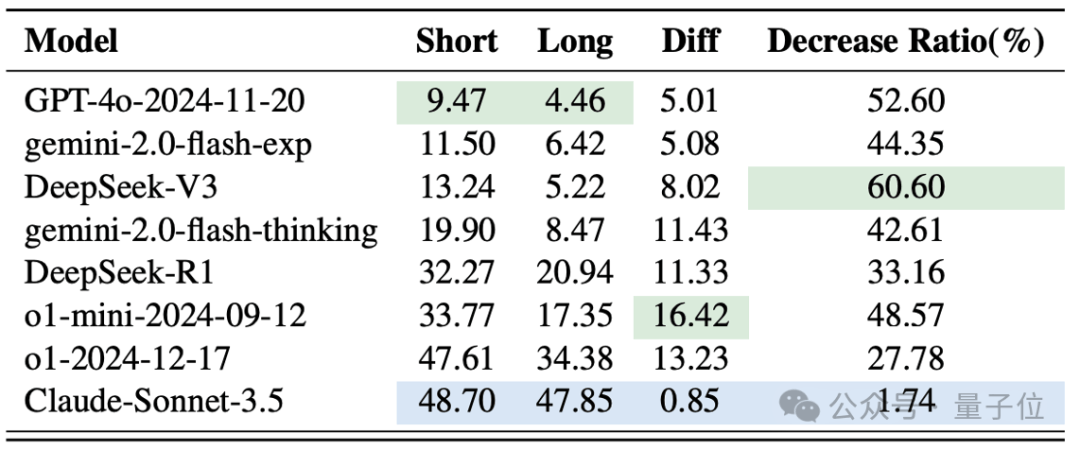
怕长文本: 文本越长,模型越容易出错!与人类解密不同,人类一旦成功找到解密方法之后,便能以近100%的成功率破解,而LLMs的“脑容量”在解密时会受到长度限制。
怕噪音干扰:明文中加点儿错别字或无关信息,模型性能“闪崩”!这暴露了模型在“猜测”而非“推理”——它们不是严格按规则解密,而是依赖文本的语义顺畅度,一旦语义被破坏,就歇菜了。
怕数字转换:加密内容里混入数字?难度瞬间飙升!LLMs在处理涉及数字的转换规则时显得尤为吃力。
“提示”依赖症:如果在Prompt里直接告诉模型是什么算法,推理模型表现会大幅提升,而通用模型提升有限。这说明推理模型在“有向”推理时更有效,但自主从示例中发现规则的能力还不足。
错误分析:模型到底错在哪儿?
研究团队对模型的错误输出进行了细致分类(遗漏/插入、姓名解密错误、语义推断、重组、推理失败等),将模型的错误分布总结为下图(左图为Chat model错误分布,右图为Reasoning model的错误分布),并发现了一些有意思的现象:
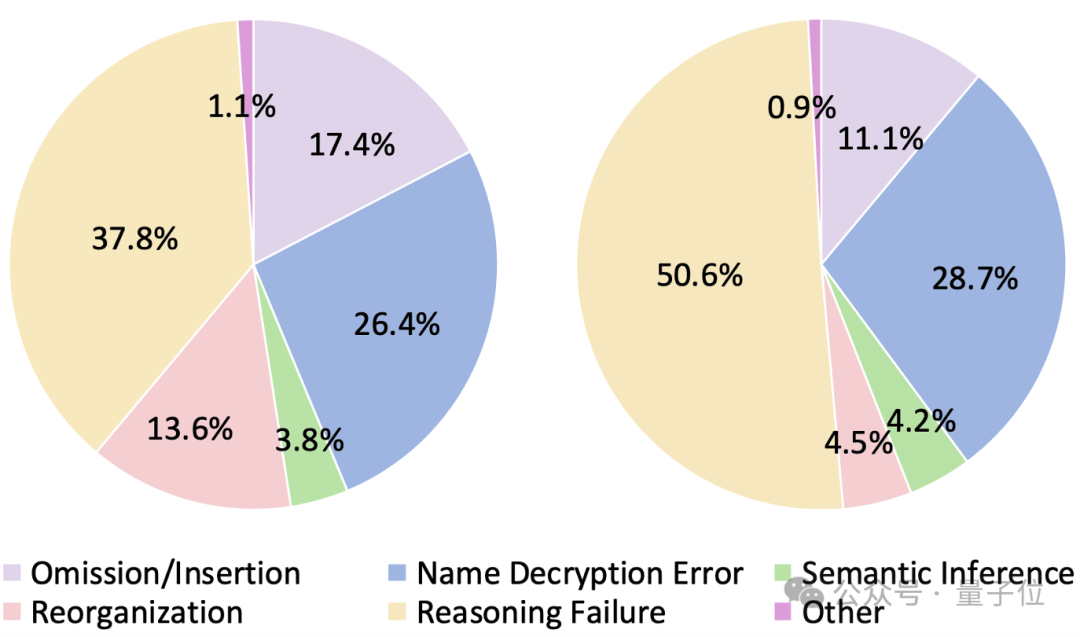
推理模型「想太多」:有时在简单的算法(比如Reverse)上,推理模型反而会“过度分析”,绕了远路最终出错。
对话模型「爱脑补」:更倾向于生成语义通顺但并未完全符合解密规则的文本,容易出现“遗漏/插入”或“重组”错误,像是在“自由发挥”。
未来展望
那么,未来的 AI 应该往哪个方向努力,才能征服密码解密这座“高山”呢?CipherBank的结果为人们指明了几个关键的突破口:
摆脱「过度语义依赖」:让模型训练出纯粹的、抽象的符号和结构化推理能力,不再仅仅依赖表面文本的“猜意思”或进行“语义补全”,尤其在处理不具备强语义规律的加密数据时。
增强「模式学习与泛化」:提升模型从少量示例中精准对比分析、高效提取隐含加密规则和密钥的能力,并能将这些规则稳健地泛化应用于各种情况,包括处理混合文本(如数字与字母)以及对抗轻微的噪音干扰。
优化「推理执行的稳定性」:改进模型的思考流程,避免在看似简单的任务上“过度思考”或陷入不必要的递归修正,确保推理过程更加直接、高效和稳定,能够精确无误地执行推断出的解密步骤。
未来,大语言模型有望在密码学领域取得更加显著的进展。
项目主页:https://cipherbankeva.github.io/
论文直达:https://arxiv.org/abs/2504.19093
测试数据:https://huggingface.co/datasets/yu0226/CipherBank